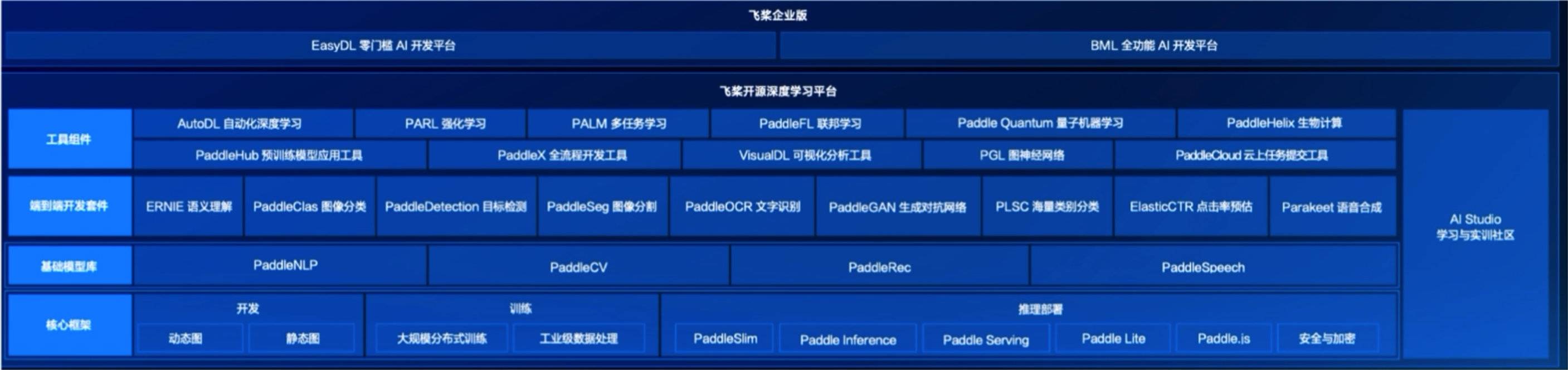
飞桨与python入门操作—实践:海量文件遍历、图像直方图统计、文本词频统计 飞桨全景图 飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,集深度学习核心训练和推理框架 、基础模型库 、端到端开发套件 和丰富的工具组件 于一体。
Python的优点 Python的设计混合了传统语言的软件工程的特点和脚本语言的易用性,具有如下特性 :
开源、易于维护、可移植
易于使用、简单优雅
广泛的标准库、功能强大
可扩展、可嵌入
所有的深度学习框架一般都有一个Python版的接口
Python数据结构 数字Number
Python Number 数据类型用于存储数值,包括整型、长整型、浮点型、复数
Python 中数学运算常用的函数基本都在math模块
字符串String
列表List
声明一个列表,并使用下标访问元素
访问最后一个元素
访问第一个元素
列表查询
查询names列表中有没有值为’superman’的元素:
元组Tuple
字典Dict Numpy库 介绍 Numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包 ,其部分功能如下:
ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组
用于对整组数据进行快速运算的标准数学函数 (无需编写循环)
用于读写磁盘数据 的工具以及用于操作内存映射文件的工具
线性代数、随机数生成以及傅立叶变换功能
使用
创建ndarray:创建数组最简单的办法就是使用array函数,它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的Numpy数组,其中,嵌套序列(比如由一组等长列表组成的列表)将会被转换成一个多维数组
Matplotlib库 介绍
Matplotlib库由各种可视化类构成,内部结构复杂
受Matlab启发,matplotlib.pylot是绘制各类可视化图形的命令字库,相当于快捷方式
使用
plt.plot()只有一个输入列表或数组时,参数被当作Y轴,X轴以索引自动生成plt.savefig()将输出图形存储为文件,默认png格式,可以通过dpi修改输出质量
实战 海量文件遍历 1 2 3 4 5 6 7 8 9 10 11 12 import zipfileimport osdef unzip_data (src_path,target_path ):if (not os.path.isdir(target_path)): z = zipfile.ZipFile(src_path, 'r' ) z.extractall(path=target_path) z.close() unzip_data('data/data10954/cat_12_test.zip' ,'data/data10954/cat_12_test' ) unzip_data('data/data10954/cat_12_train.zip' ,'data/data10954/cat_12_train' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import os""" 通过给定目录,统计所有的不同子文件类型及占用内存 """ size_dict = {} type_dict = {} def get_size_type (path ):files = os.listdir(path) for filename in files: temp_path = os.path.join(path, filename) if os.path.isdir(temp_path): get_size_type(temp_path) elif os.path.isfile(temp_path): type_name=os.path.splitext(temp_path)[1 ] if not type_name: type_dict.setdefault("None" , 0 ) type_dict["None" ] += 1 size_dict.setdefault("None" , 0 ) size_dict["None" ] += os.path.getsize(temp_path) else : type_dict.setdefault(type_name, 0 ) type_dict[type_name] += 1 size_dict.setdefault(type_name, 0 ) size_dict[type_name] += os.path.getsize(temp_path)
1 2 3 4 5 6 7 8 path= "data/data10954/" get_size_type(path) for each_type in type_dict.keys(): print ("%5s下共有【%5s】的文件【%5d】个,占用内存【%7.2f】MB" % (path,each_type,type_dict[each_type],\ size_dict[each_type]/(1024 *1024 ))) print ("总文件数: 【%d】" %(sum (type_dict.values())))print ("总内存大小:【%.2f】GB" %(sum (size_dict.values())/(1024 **3 )))
图像直方图统计 灰度直方图概括了图像的灰度级信息,简单的来说就是每个灰度级图像中的像素个数以及占有率,创建直方图无外乎两个步骤:
统计直方图数据:首先要稍微理解一些与函数相关的术语,方便理解其在python3库中的应用和处理
BINS: 在上面的直方图当中,如果像素值是0到255,则需要256个值来显示直方图。但是,如果不需要知道每个像素值的像素数目,只想知道两个像素值之间的像素点数目怎么办?例如,想知道像素值在0到15之间的像素点数目,然后是16到31······240到255。可以将256个值分成16份,每份计算综合。每个分成的小组就是一个BIN(箱)。在opencv中使用histSize表示BINS。
DIMS: 数据的参数数目。当前例子当中,对收集到的数据只考虑灰度值,所以该值为1。
RANGE: 灰度值范围,通常是[0,256],也就是灰度所有的取值范围。
统计直方图同样有两种方法:使用opencv统计直方图,函数如下:
cv2.calcHist([images], [channels], mask, histSize, ranges[, hist[, accumulate ]])
imaes:输入的图像
channels:选择图像的通道
mask:掩膜,是一个大小和image一样的np数组,其中把需要处理的部分指定为1,不需要处理的部分指定为0,一般设置为None,表示处理整幅图像
histSize:使用多少个bin(柱子),一般为256
ranges:像素值的范围,一般为[0,255]表示0~255
统计其在所有通道上的图像直方图 1 2 3 4 5 6 7 8 import cv2import numpy as npfrom matplotlib import pyplot as pltimg = cv2.imread('data/data131367/nezha.jpg' ,1 ) plt.hist(img.reshape([-1 ]),256 ,[0 ,256 ]); plt.show()
统计其在单通道上的图像直方图 1 2 3 4 5 6 7 8 9 import cv2from matplotlib import pyplot as pltimg = cv2.imread('data/data131367/nezha.jpg' ,0 ) histr = cv2.calcHist([img],[0 ],None ,[256 ],[0 ,256 ]) plt.plot(histr,color = 'b' ) plt.xlim([0 ,256 ]) plt.show()
统计其在三通道上的图像直方图 1 2 3 4 5 6 7 8 9 10 11 import cv2from matplotlib import pyplot as pltimg = cv2.imread('data/data131367/nezha.jpg' ,1 ) color = ('b' ,'g' ,'r' ) for i,col in enumerate (color): histr = cv2.calcHist([img],[i],None ,[256 ],[0 ,256 ]) plt.plot(histr,color = col) plt.xlim([0 ,256 ]) plt.show()
灰度直方图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import sysimport numpy as npimport cv2import matplotlib.pyplot as pltdef main (): img=cv2.imread('data/data131367/nezha.jpg' ,0 ) n = np.array(img) xy=xygray(img) x_range=range (256 ) plt.plot(x_range,xy,"r" ,linewidth=2 ,c='black' ) y_maxValue=np.max (xy) plt.axis([0 ,255 ,0 ,y_maxValue]) plt.xlabel('gray Level' ) plt.ylabel("number of pixels" ) plt.show() def xygray (img ): rows,cols=img.shape print (img.shape) xy=np.zeros([256 ],np.uint64) for r in range (rows): for c in range (cols): xy[img[r][c]] += 1 print (xy.sum ()) return xy main()
文本词频分析 词频分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import jieba with open ('/data/data131368/test.txt' , 'r' , encoding='UTF-8' ) as novelFile: novel = novelFile.read() stopwords = [line.strip() for line in open ('/data/data131368/stop.txt' , 'r' , encoding='UTF-8' ).readlines()] novelList = list (jieba.lcut(novel)) novelDict = {} for word in novelList: if word not in stopwords: if len (word) == 1 : continue else : novelDict[word] = novelDict.get(word, 0 ) + 1 novelListSorted = list (novelDict.items()) novelListSorted.sort(key=lambda e: e[1 ], reverse=True ) topWordNum = 0 for topWordTup in novelListSorted[:10 ]: print (topWordTup) from matplotlib import pyplot as pltx = [c for c,v in novelListSorted] y = [v for c,v in novelListSorted] plt.plot(x[:10 ],y[:10 ],color='r' ) plt.show()
生成词云图片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from wordcloud import WordCloud,ImageColorGeneratorimport jiebaimport matplotlib.pyplot as plt from imageio import imreadbg_pic = imread('bg.png' ) wordcloud = WordCloud(mask=bg_pic,background_color='white' ,\ scale=1.5 ,font_path='data/data131368/msyh.ttc' ).generate(' ' .join(novelDict.keys())) plt.imshow(wordcloud) plt.axis('off' ) plt.show() wordcloud.to_file('父亲.jpg' )





































 微信
微信 支付宝
支付宝